
Application
Solutions pour les systèmes d’apprentissage automatique
Solutions de connectivité à haut débit et à haute puissance pour les systèmes d’apprentissage automatique et d’inférence.
Notre monde est plus connecté que jamais avec des milliards de dispositifs IoT à la périphérie qui génèrent collectivement une énorme quantité de données. Les informations tirées de ces données changent notre façon de faire des affaires, d’interagir avec les gens et de vivre notre vie quotidienne. Ces informations sont générées en traitant les données par des réseaux neuronaux pour reconnaître les modèles et catégoriser les informations. Une fois le réseau neuronal formé, le modèle peut être déployé pour traiter et analyser de nouvelles données. C’est ce qu’on appelle communément l’inférence. La reconnaissance vocale, la détection d’objets, la classification d’images et les moteurs de personnalisation et de recommandation de contenu sont des applications quotidiennes qui peuvent tirer parti de l’inférence.
Les utilisateurs finaux exigent des informations en temps réel dans ces applications, ce qui génère de l’inférence sur les appareils mobiles et à la périphérie. Les différents types d’accélérateurs matériels tels que les FPGA, les GPU et les ASIC sont utilisés pour classer et caractériser les données. Chacun de ces dispositifs diffère par la puissance de traitement et la consommation d’énergie, chacun présentant des avantages en fonction de la charge de travail. Certains de ces dispositifs sont utilisés à la fois pour la formation et l’inférence, tandis que d’autres sont dédiés à l’un ou l’autre.
- Les FPGA (Field Programmable Gate Arrays, matrices prédiffusées programmables par l’utilisateur) sont couramment utilisés pour accélérer les processus de réseau et de stockage et décharger le processeur de ces tâches.
- Les unités de traitement graphique (GPU) sont conçues pour gérer des tâches simultanées et peuvent traiter de grands ensembles de données plus efficacement que les processeurs.
- Les circuits intégrés spécifiques aux applications, ou ASIC, sont des processeurs conçus pour des charges de travail ou des tâches spécifiques pour permettre un rendement énergétique optimal.
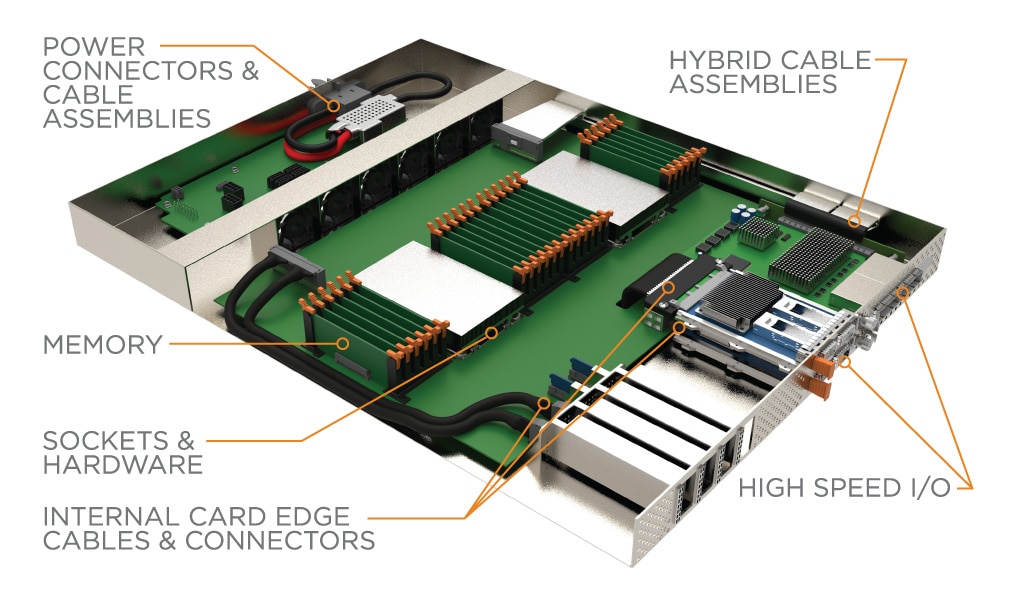
Les accélérateurs matériels sont souvent connectés à d’autres périphériques de calcul et de stockage, regroupés dans de vastes tissus et connectés au réseau plus vaste. Les connexions réseau peuvent tirer parti de protocoles tels qu’Ethernet et InfiniBand, qui utilisent normalement des formats d’E/S à haut débit tels que OSFP et QSFP-DD. PCIe est utilisé pour connecter les périphériques de stockage, les cartes d’interface réseau (NIC) et les accélérateurs matériels au processeur. La famille de connecteurs et de câbles Sliver de TE est conforme à la spécification SFF-TA-1002 et permet à ces appareils de se connecter et de fonctionner à des vitesses PCIe Gen 5 et Gen 6.
Compute Express Link (CXL) et Gen-Z sont des protocoles émergents et rapidement adoptés qui visent à supprimer le goulot d’étranglement de la mémoire en activant une mémoire cache cohérente. Cela contribue à la mise en place de nouvelles architectures, lesquelles rendent nécessaire le recours à des tissus PCIe externes qui utilisent des produits de connectivité comme CDFP et Mini-SAS HD.
Le système de câbles et de connecteurs de fond de panier haute vitesse STRADA Whisper de TE peut permettre la modularité du système en offrant une connexion aveugle à des vitesses de 112 Gbit/s PAM-4.
 e
e

 e
e
 e
e
















